
翻譯自 The Next Platform : ARM GETS CLOSER TO CREATING FULL-BLOWN SERVER CPU DESIGNS
獲得新的計算引擎並將其投入 Server 使用需要太長時間,每個人都在抱怨這一點。伴隨著新一代晶片的推出,客戶因為想要更高的性能和更好的性價比,而那些製造CPU、GPU和其他計算引擎的人也同樣不耐煩。他們希望壓制競爭對手,賺更多的錢。
在本週的Hot Chips 2023 會議上,Arm Ltd在宣布上市後展示了其“Demeter” V2核心,該公司還推出了“Genesis” N2計算子系統,或稱之為CSS知識套件(intellectual package)。(本文將會單獨深入詳細介紹V2核心。 Genesis的這項努力有可能比過去更快地將Arm CPU投入市場使用。
多年來,Arm一直在朝向為客戶組裝成熟的CPU,以便他們可以進行修改並更快地投入市場。早在2000年代末,當Arm主導了智慧型手機領域,伺服器製造商正在思考利用Arm影響本質壟斷的X86架構系統,然而,這種開發方式需要伺服器晶片設計師從Arm架構許可證階段著手進行開發。比起從ISA(指令集架構)開始設計要好,但是仍然是一種非常昂貴且耗時的建立伺服器晶片的方式,從 ISA 開始需要進行大規模的軟體移植工作,而這個世界沒辦法接受這種模式。
在Broadcom、高通、AMD 和三星等老牌半導體巨頭以及Calxeda和Applied Micro 等新創公司多次嘗試Arm 伺服器晶片失敗,以及Cavium的ThunderX和ThunderX2 CPU取得了一些有限的成功,Arm 決定將其推出 Neoverse 的工作於 2018 年 10 月推出,它不僅提供了伺服器晶片核心的路線圖,還提供了用於將這些核心轉變為適當的CPU的參考架構,並混合了其他 Arm 的 IP 像是 on-die mesh network (譯註: 用於 CPU 互連)和第三方記憶體、PCI-Express 和乙太網路控制器等等。這些 Neoverse 設計是針對台積電的特定製程節點量身定制的,這使得伺服器晶片製造商更容易更快的完成這些工作。
我們從來不確定Neoverse解決方案是否比架構許可證 (architectural license) 便宜還是貴。從多個不同角度來討論,Neoverse的工作量更大,但與Arm架構許可證相比,自由度有限。也許更重要的是,正如我們在一年前的文章Arm Is the New RISC/Unix, RISC-V Is The New Arm一文中指出的一樣,如果Arm無法比開放原始碼的RISC-V ISA和設計更便宜,那麼它就必須更快。無論如何,由於客戶的不耐煩,Arm都必須更快。
以下是2022 年 9 月公佈的最新 Neoverse 路線圖::
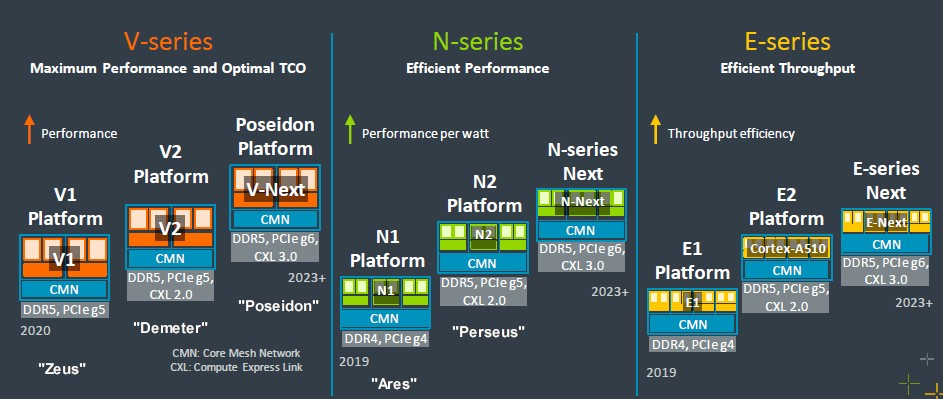
最初,只有一個核心系列 – N 系列 – 但 Arm 將其分為三個核心系列和三個相應的平台,每個平台都針對系統市場的不同部分。N 系列核心和平台針對主流伺服器非常注重的(工作負載/每瓦效能驅動) 設計,而 V 系列具有強大向量處理運算能,針對運算密集型工作負載,例如 AI 訓練和推理以及 HPC 模擬和建模。E 系列旨在實現吞吐量運算,並且不僅針對更高的每瓦效能進行了最佳化,而且還以比 N 系列更低的熱封裝實現了最大吞吐量。現在不僅有三個系列的內核和平台,還有兩種方法:DIY 和 CSS。
所以現在新的 Neoverse 路線圖看起來像是硬塞進去了 CSS 選項:
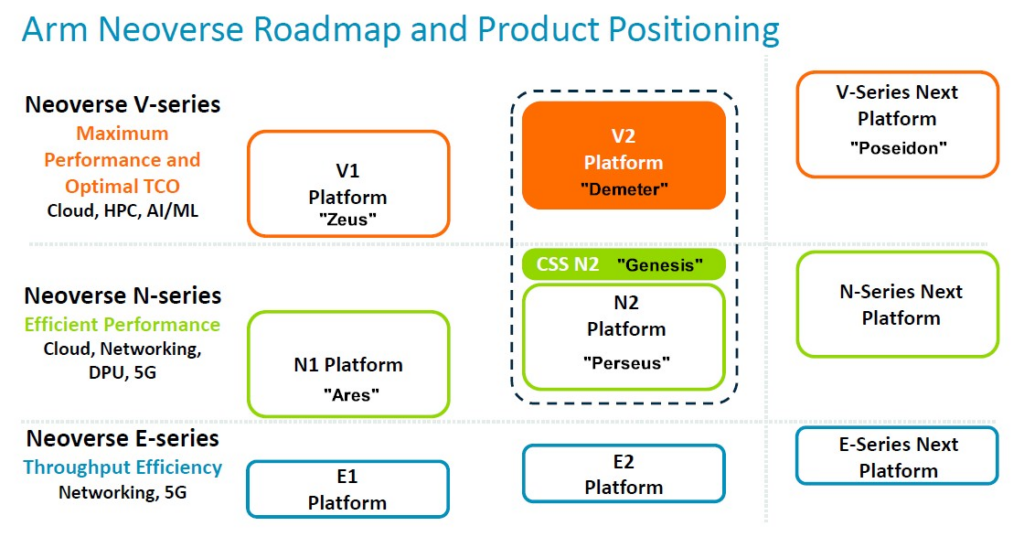
我們已經為我們所知的每個核心和平台添加了代號。
Neoverse 計畫使晶片公司在設計方面提前取得了優勢,許多公司都加入了這一行列。富士通的 A64FX 晶片比當前任何供應商都早得多(早於Neoverse計畫之前的幾年),在許多方面都可以被視為“Kronos”V0 實作,因為它發明了可擴展向量擴展(SVE)並將其引入512-bit 向量,將極限拉到像 Intel AVX-512 。亞馬遜在其 Graviton1 晶片中使用了原始 Neoverse 世代中的「Maya」基於Cortex A72,在其 Graviton2 晶片中使用了「Ares」基於N1,在其Graviton3 晶片中使用了「Zeus」基於V1。十多年前,Nvidia 最初使用其 Arm 架構許可來創建“Denver”伺服器處理器,但已改用“Grace”CPU 晶片的 V2 內核現在即將上市。AmpereComputing 的 Altra 和 Altra Max Arm CPU 中使用 N1 內核,但現在正在開發客製化內核。顯然,阿里巴巴已經為其倚天 710 處理器定制了 Arm v9 核心,如果這是真的,那麼 Nvidia 的 Grace 並不是市場上第一個 Arm v9 核心。印度政府正在其“Aum”A48Z 處理器中使用 V1 核心。
還有其他的,但這些是最重要的幾家公司。他們都花費了大量資金來創建 Arm 伺服器晶片。但這與金錢一樣重要的是時間。眾所周知,愛因斯坦證明了時間就是瘋狂的金錢,也證明了能量就是瘋狂的物質(Einstein proved that time is money gone wild as well as proving energy is matter gone wild)。
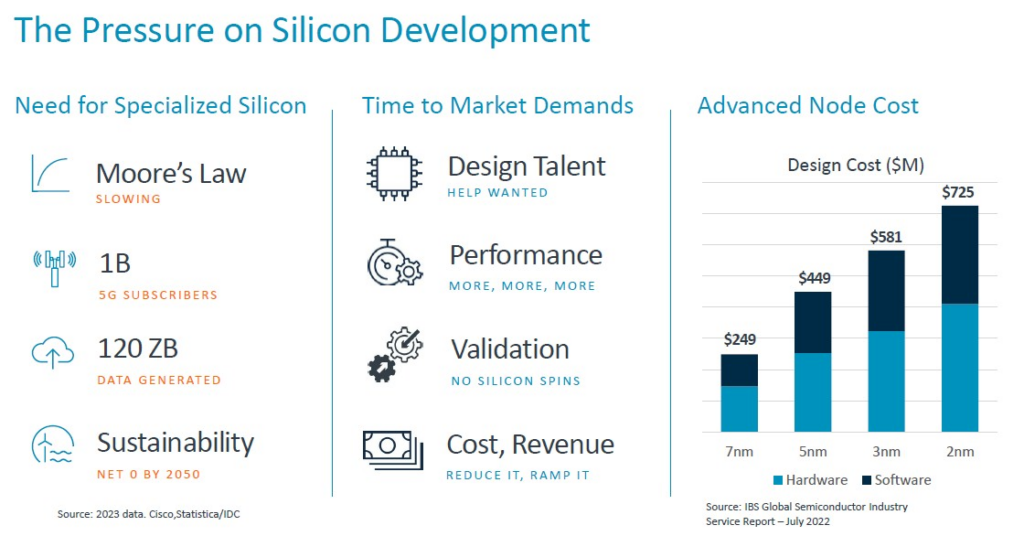
正如 Arm 產品管理高級總監 Jeff Defilippi 在 Hot Chips 上的 Arm 演講之前解釋的那樣,隨著摩爾定律走到盡頭,對專用晶片的需求不斷增長,晶片設計人員面臨的壓力也在不斷增加。如上圖所示,隨著電晶體尺寸的縮小,設計晶片的成本也在上升,而在 7 奈米節點之後,每個電晶體的製造成本也在上升,儘管這張圖沒有顯示。
Arm 的CSS 知識套件旨在加快設計速度,從某種意義上說,時間就是金錢,至少可以將金錢轉化為節省的時間,正如愛因斯坦所證明的那樣正如愛因斯坦再次證明的那樣,節省的時間就是通過更早的銷售節省的金錢和獲得的金錢。(我們假設CSS 的成本比常規IP 許可更高,因為它包含更多內容,但風險要低得多,並且成本和風險的乘積(不是總和,而是乘積,因為這些是乘法效應而不是累積效應)因此較低.)
以下是CSS包的概念示意圖:
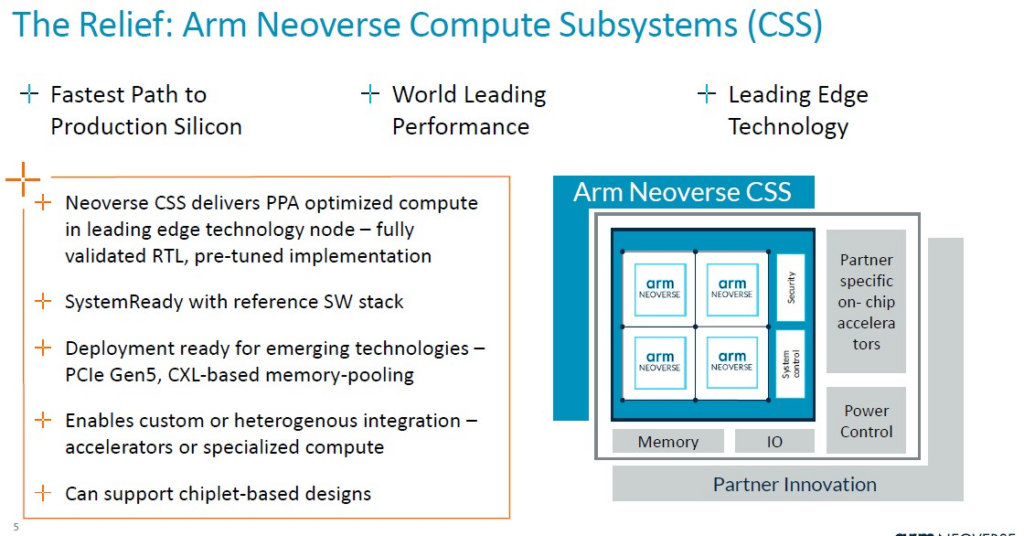
以下是它與 SoC 授權、IP 授權和架構授權的比較:
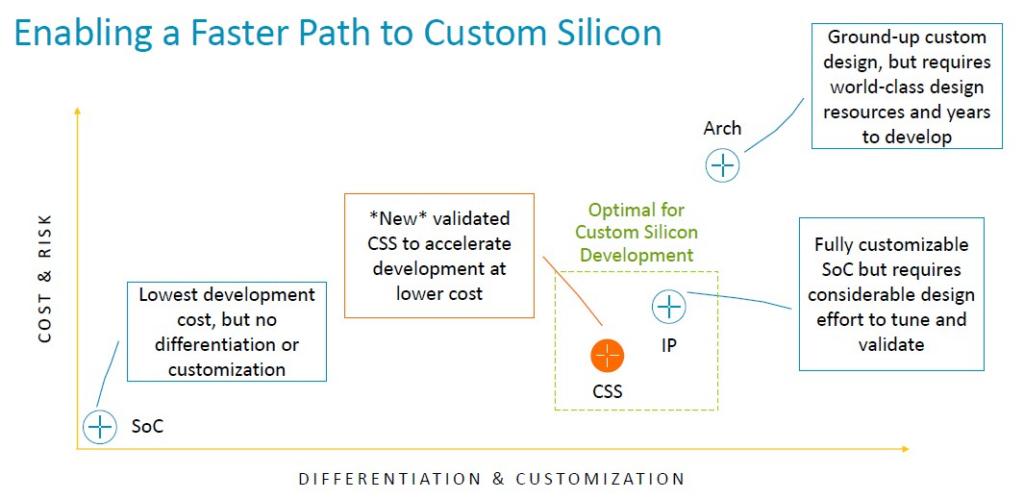
「本質上,這個產品是 Arm 拼接在一起的多核心設計,」Defilippi 解釋道。「這就是互連(interconnect)、CPU集群、虛擬化 IP – 我們將它們縫合在一起,進行驗證,並將其作為生產就緒的 RTL 可交付成果交付給我們的客戶。除了 RTL 之外,我們還提供與之相關的額外好處:我們提供實作套件(implementation package)、平面圖、實作指令(implementation scripts)和實體 IP 庫,這些都是在領先的技術上達到所需性能和功耗封閉環境所必需的。領先的技術。我們提供完整的軟體參考堆疊。這包括從韌體、電源管理、系統管理,到系統所需的執行階段安全性等所有內容。我們提供完整的軟體參考堆疊(reference stack),以確保軟體開發從第一天就能開始,讓我們的客戶能順利起步。最後但同樣重要的是,我們還包括了超越單純的工藝節點的領先技術。每年都會有新的令人興奮的東西問世,現在就有一個例子就是 CXL 記憶體擴展池(CXL memory expansion pooling)。
現在想像一下,特別是如果您位於中國、印度、非洲,甚至位於美國或歐洲的並且注重成本的超大規模企業、雲端建構商或 HPC 中心,並且沒有大量熟悉高級伺服器 CPU 的熟練工程師設計或正確設計和測試它們的工具,以便快速推出下一代晶片。那麼 CSS 方法不僅可以大大加快速度,而且可以從一開始就製造出晶片。
但時間很重要,以下是 Arm 如何計算透過 CSS 套件與使用普通 IP 授權相比節省的時間:
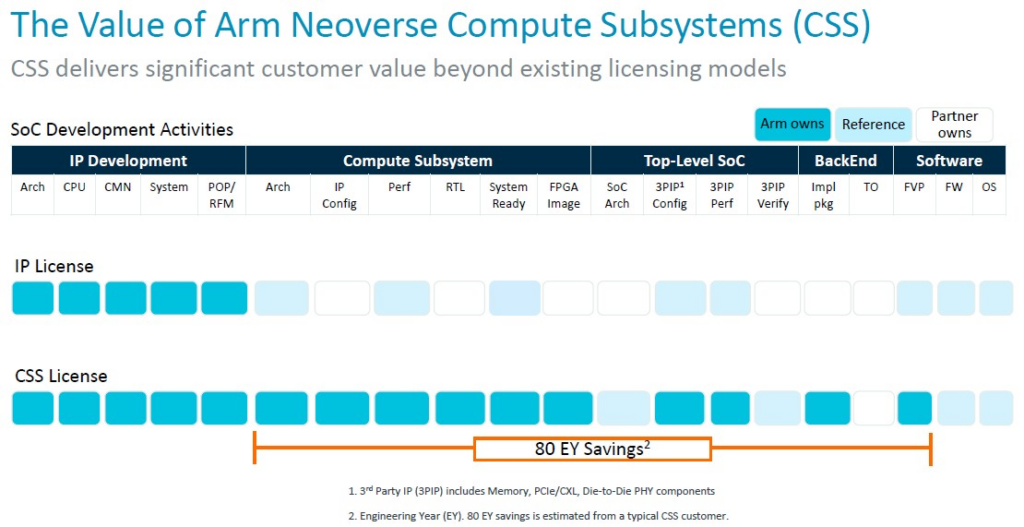
每年可以節省 80 個工程師的時間省下的成本是相當可觀的,特別是在還有自訂的自由度時的情況下。
問題是:與晶片製造商所做的大量工作相比,CSS 設計的價值有多大?將晶片從概念變為伺服器、網路設備或儲存陣列需要多少成本?這比使用 Intel 或 AMD 的 X86 伺服器或 AmpereComputing 的 Arm 晶片便宜多少?這一切是否值得努力花費這麼多工夫(the trouble)?
嗯,隨著AWS 和阿里巴巴製造自己的Arm 晶片,有傳言稱谷歌也將這樣做,微軟、騰訊和百度(以及阿里巴巴、谷歌和甲骨文)也使用AmpereComputing 的Altra Arm 晶片,似乎這樣做是值得的工夫(the trouble)。Arm的CPU可以為它們節省成本,並且在它們的伺服器叢集中佔據越來越大的份額。而且,通過自己的努力以及與Ampere Computing的緊密合作,它們擁有更多的直接控制權。
當然,超大規模廠商和雲端建構商仍會購買大量英特爾和 AMD CPU。但正如我們多次說過的那樣,這將是為了支援舊版 Windows Server,有時甚至是 Linux 應用程序,他們會故意對基於它們的實例(instances)收取額外溢價費用- 正如英特爾和AMD為底層晶片所做的那樣。沒有人在我們看到的分層上串通一氣,但英特爾和 AMD 沒有動力與 Graviton 和其他公司競爭。他們只需讓超大規模和雲規模的15%、20%、25%轉向Arm,然後他們可以在不陷入價格戰的情況下滿足85%、80%和75%的較大規模需求。
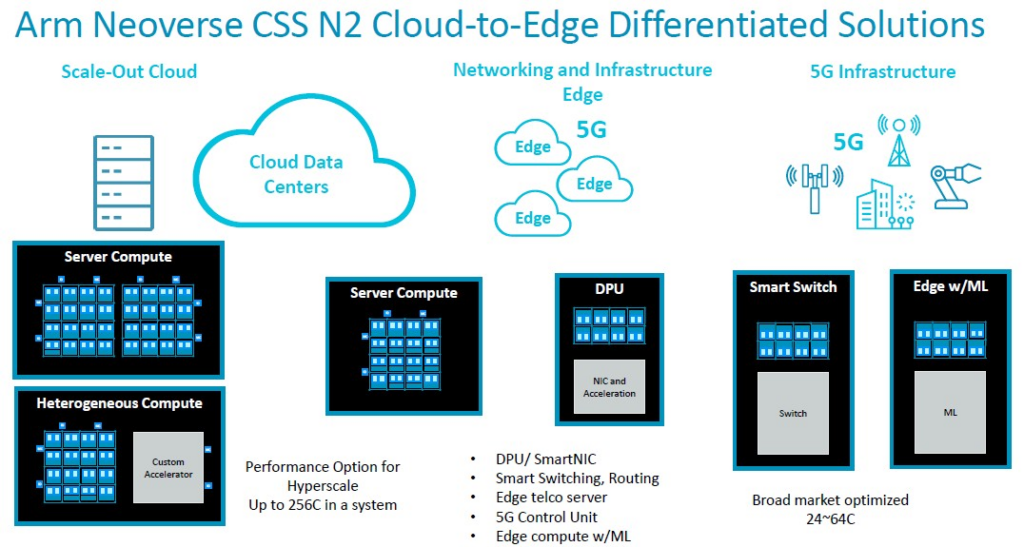
CSS實現的“Perseus” N2核心的互連網路規模從24核擴展到64核,並且可以使用UCI-Express(而非CCIX)或專有互連將其中四個核心基於客戶的需求利用 chiplet 組合在一個封裝中,以擴展到插槽中的256 個核心。
考慮到許多現代處理器將執行預期的 HPC 和 AI 向量數學運算,現在沒有為V2設計提供CSS的方案有點可惜。也許這會發生——我們強烈鼓勵這樣做,且在未來幾年內,未來的V3設計可能會有這個選項。目前,Arm只是從路線圖中間的CSS開始努力-只針對N2設計。
現在,準備好查看一些關於Genesis CSS N2包的精美原理圖和模組圖,這些圖是由Arm高級工程師、晶片IP設計師的首席系統架構師Anitha Kona呈現的。
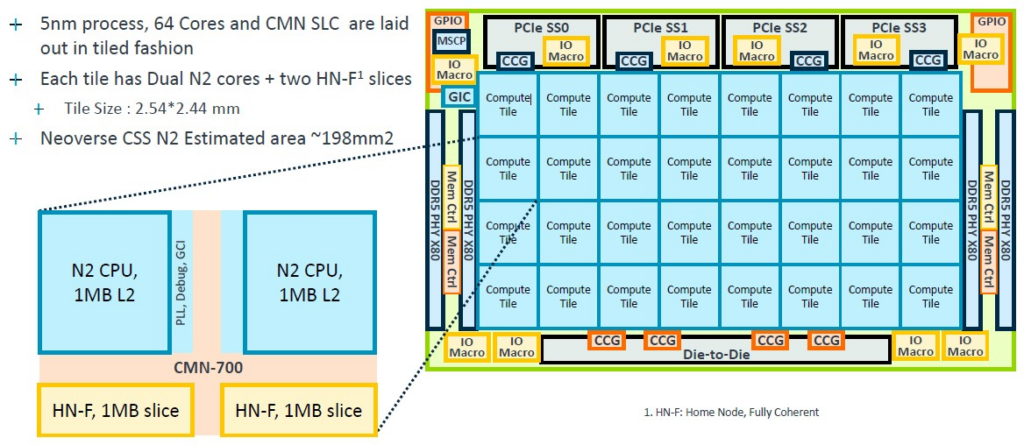
這是台積電 5 奈米 Genesis 封裝中的 64 核心基礎模組:
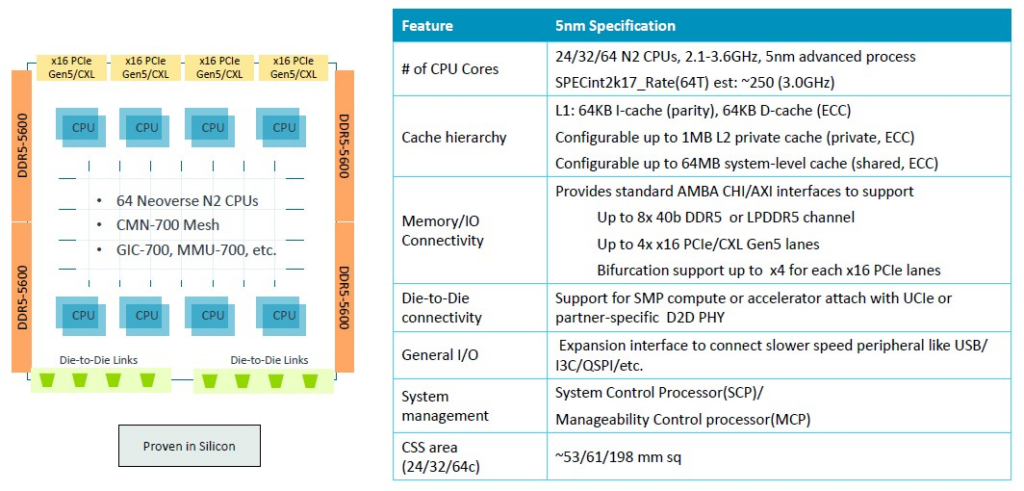
以下是細部的區塊設計圖 (block disgram)
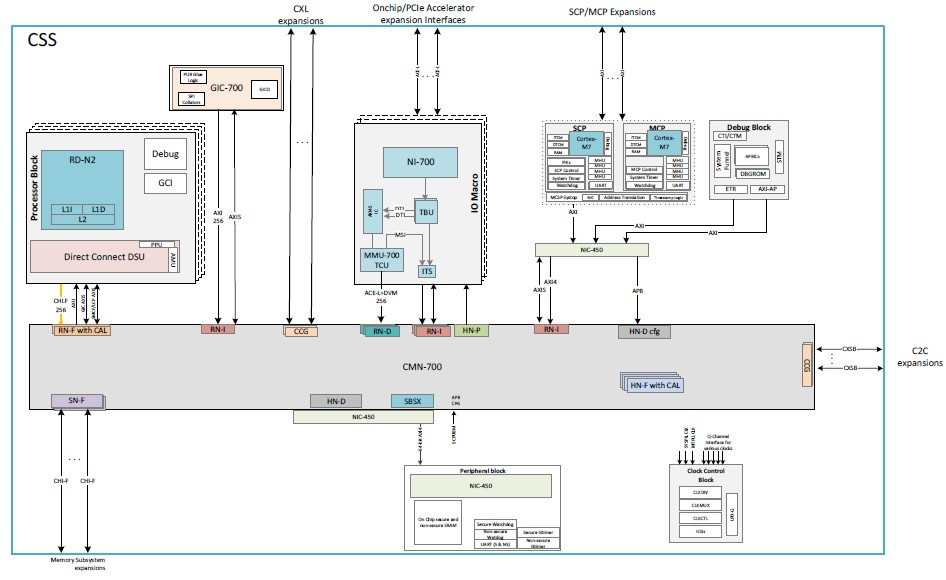
CSS N2 套件符合 SystemReady 標準,符合 Arm 基礎系統架構 1.0、Arm 伺服器基礎系統架構(Arm Server Base System Architecture) 6.1 和 Arm 伺服器基本開機需求(Arm Server Base Boot Requirements ) 1.2。
N2 核心是 Arm 的第一個 Armv9 實現,V2核心也應該不會落後太遠,因為現在Grace已經上市,據我們所知,Nvidia 從 Arm 獲得了 V2 核心。,而且據我們所知,Nvidia也完成了V2核心的開發。有可能Nvidia和Arm合作設計了V2核心,就像富士通和Arm在我們戲稱為V0核心的項目上合作一樣。以下是N2核心的處理器模組示意圖:
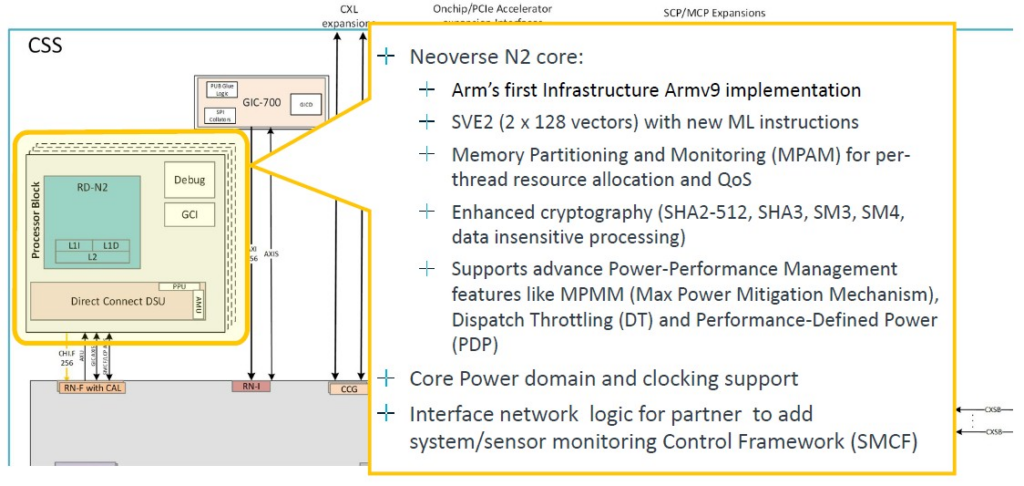
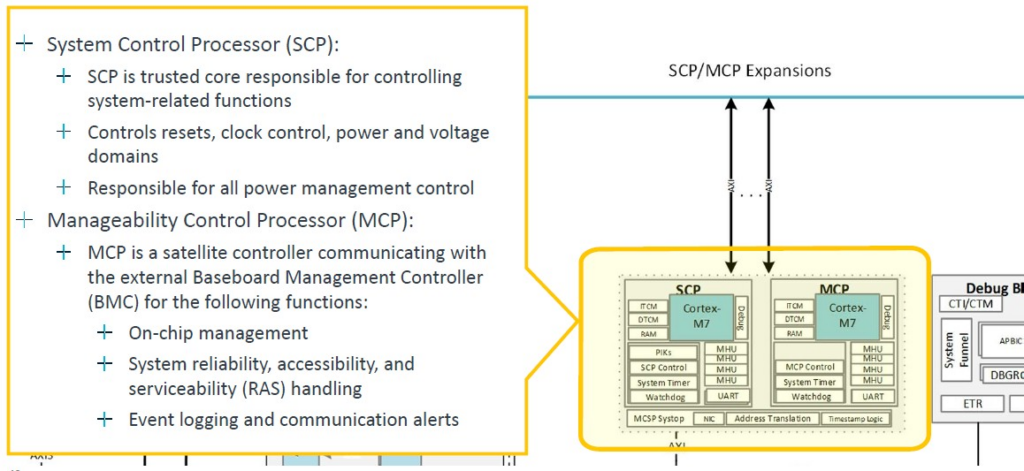
兩個 SVE2 128 位元向量還不錯,但 V2 有四個。這就是需要 CSS V2 產品的地方,希望很快不會出現代號為「Exodus」的情況。就像,呃,現在。無論如何,這是系統控制和管理的深入內容:
系統記憶體管理單元和中斷控制器的放大圖:
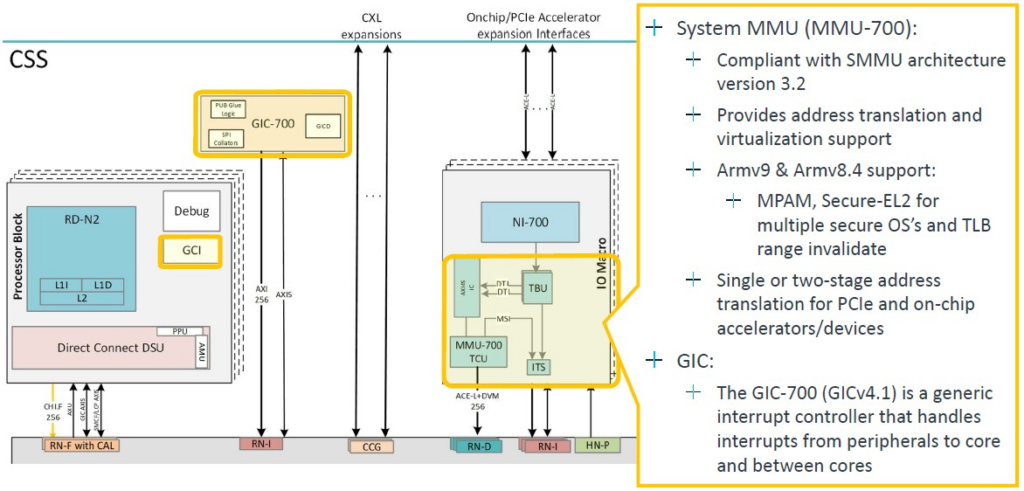
CPU 核心使用 CMN-700 mesh network 相互連結,該 mesh network 設計已經存在了幾年,並針對 Armv9 設計進行了調整,運作頻率為 2 GHz:
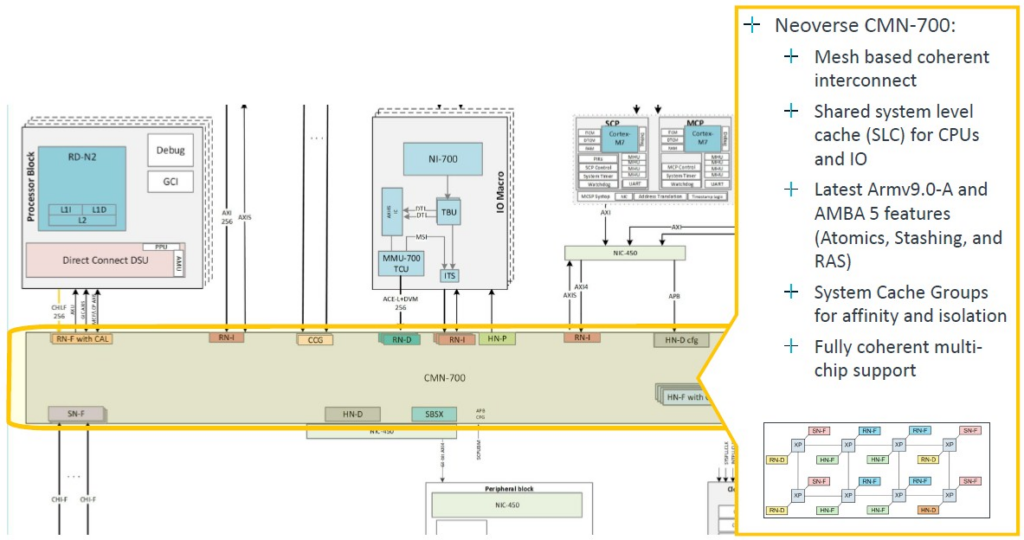
Genesis套件括一個N2 CPU的平面圖,可以從24核擴展到64核,64核的平面圖如下:
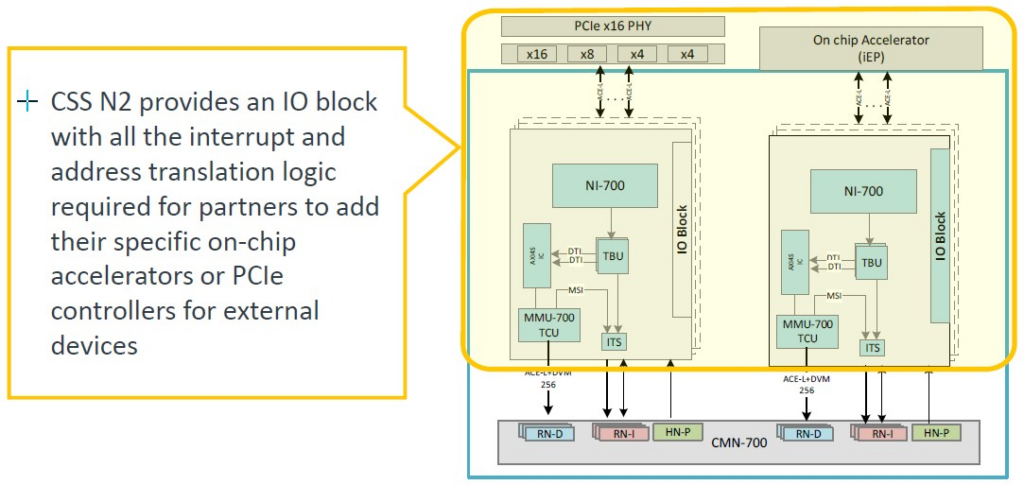
CSS N2 套件還包括一個加速器連接塊,允許卡入 PCI-Express 以及 CXL 控制器:
有一些互連允許兩個或四個64核N2塊連接在一起。一對晶片使用晶片對晶片PHY來實現直接的對稱多處理(SMP)連接(譯註:像是 Mac M2 CPU 的設計),CXL PHY用於交叉連接一對這樣的連接,建立一個具有256核的四路封裝,如下所示:
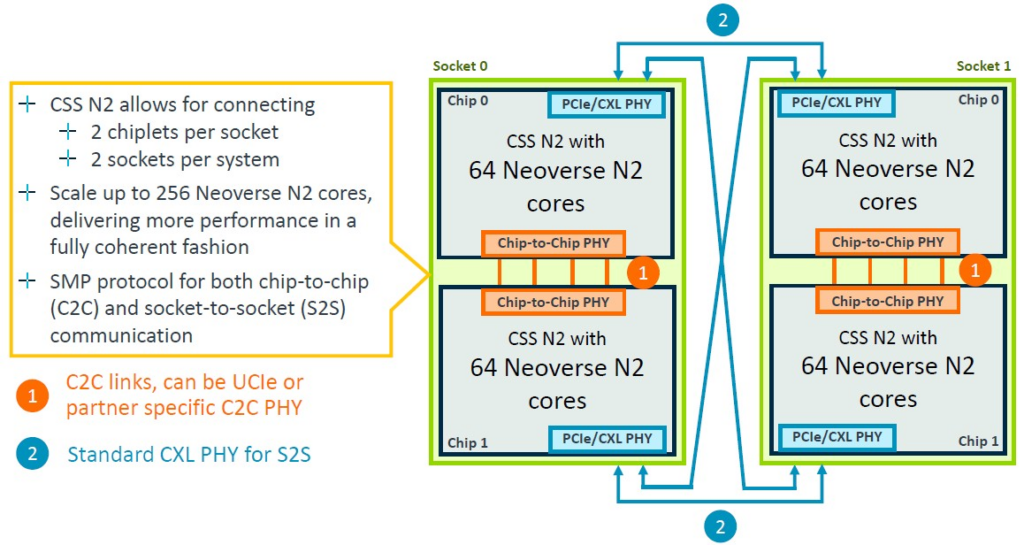
以下是關於這些SMP連接如何工作的更詳細資訊:
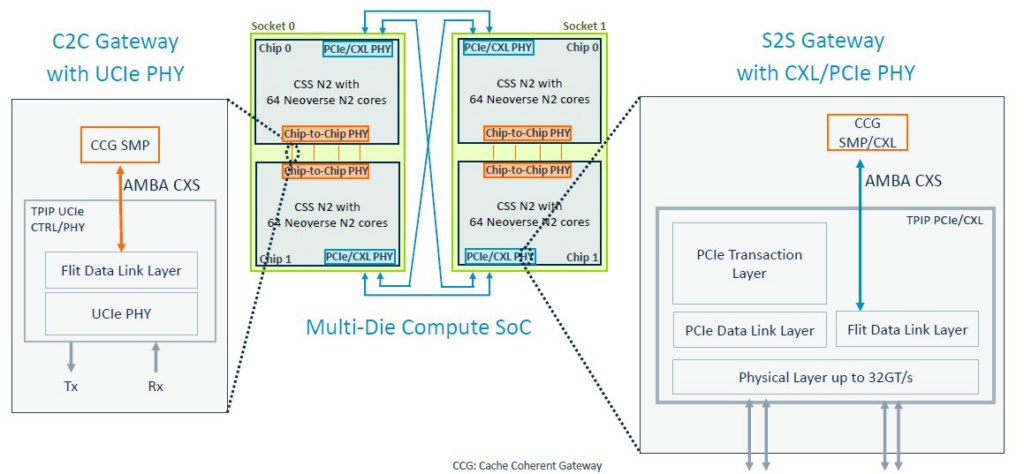
PCI-Express/CXL區塊顯然允許在mesh interconnect 上嵌入的任何記憶體控製器之上進行CXL Type 3記憶體擴展。(如果記憶體控製器和乙太網路控製器是Genesis包的一部分,那將非常有幫助。)
最後,以下是Genesis套件的一部分的軟體內容:
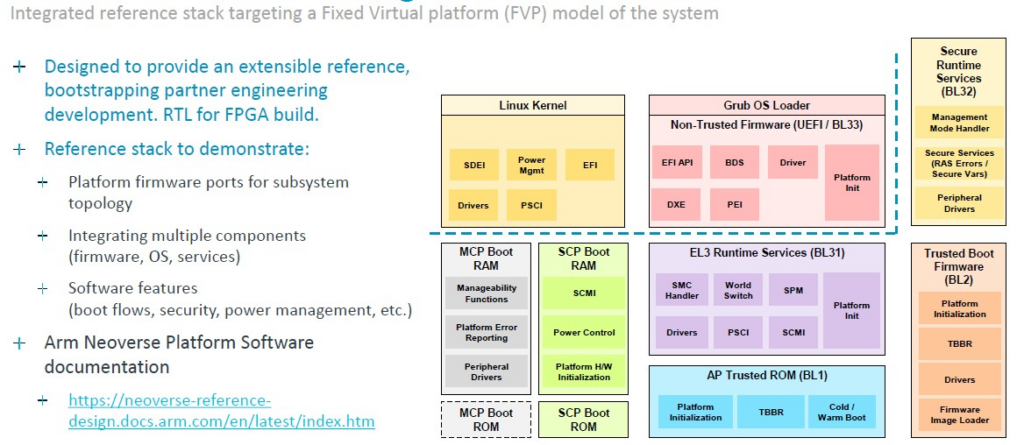
綜合考慮所有這些,Kona表示,持有Genesis IP套件許可證可以得到 CSS N2 stack,根據記憶體、I/O、加速器和物理拓撲(physical topology 實際設計)進行差異化,從計畫啟動到可工作的晶片只需驚人的13個月,並節省了80個工程師/年的開發工作。這是來自兩個不同Arm合作夥伴的兩個不同統計資料,他們是Genesis的早期採用者,因此要小心將這兩家公司的資料合併成一個可行的承諾。而且顯而易見的事,採用這樣的 Arm CPU 晶片設計可以節省無論是時間還是金錢(時間也是金錢)。
我們期待著看到與CSS N2套件類似的V系列和E系列的同類型產品。
註:本文使用 Google 翻譯,ChatGPT 和本人調整以節省時間,若有錯誤敬請見諒