
很有趣的文章,比起標題,內文介紹技術的部份才更有趣
未校稿 Gemini 直翻中文,僅供個人參考用
原文:OTHER THAN NVIDIA, WHO WILL USE ARM’S NEOVERSE V2 CORE?
原文下面有些討論也頗有趣的
我們正努力消化最近密集舉辦的 Hot Interconnects、Hot Chips、Google Cloud Next 和 Meta Networking @ Scale 等大型研討會資訊。這些研討會幾乎在同一時間舉行,包含了大量的發表內容。我們將一如既往地採用條理縝密的方法,找出有趣的部分,並分析我們所見所聞。
這次,我們將著眼於即將公開的 Arm Ltd. 公司正式推出的「Demeter」Neoverse V2 核心。
如果 Demeter 核心設計早五年甚至十年推出,那將會是一件大事,因為當時對於許多想要製造 Arm 伺服器晶片的公司來說,設計優秀的核心是一項非常艱巨的任務。正如今年 Hot Chips 上公佈的「Genesis」運算子系統 (CSS) 一樣,設計一款優秀的處理器似乎也並非易事。超大規模運算業者和雲端建構商一直希望的,並不是設計處理器,而是能夠針對其工作負載進行大量客制化處理器。大型企業有時也會有這樣的需求,而各種規模的企業類別(例如有特定工作負載需求的團體)也希望如此。
但是處理器供應商 (并非所有供應商都是製造商,也并非所有製造商都是供應商) 無法提供大量客製化服務,因為每一代製造多種變體的成本非常高昂。我們所看到的變體實際上只是啟用或禁用少數設計中固有的一些功能,這既是受晶圓區段良率所迫,也是為了透過功率閘技術人工創建變體並對零件收取額外費用。
Demeter 核心是 ARM 公司迄今为止專為伺服器設計的最佳核心,它也是首個實現於 2021 年 3 月宣布的 Armv9 架構的設計。因此,Nvidia 可以僅授權此核心和其他组件用于其 72 核「Grace」伺服器 CPU,該 CPU 对于 Nvidia 的系统架构支持傳統 HPC 模拟和建模工作负载的全 CPU 运算以及提供輔助内存和计算能力至关重要。Demeter 核心擁有四个 128 位 SVE2 向量引擎,肯定会为运行經典 HPC 工作负载以及某些 AI 推理工作负载 (那些不太庞大的,可能不包含大多数大型语言模型) 甚至在某些情况下重新训练 AI 模型提供强大的引擎。凭借设计中可能包含 16 到 256 个核心,其浮点运算性能肯定会非常强大。
我们只是想知道除了 Nvidia 以外,还有谁会在他们的 CPU 设计中使用 Demeter 核心。
AWS 幾乎肯定會在其未來的 Graviton4 自研伺服器處理器中採用 V2 核心,該處理器目前在其 Graviton3 處理器中使用「宙斯」V1 核心。阿里巴巴在其自研的 128 核倚天 710 處理器中使用 Neoverse「Perseus」N2 核心,如果它看到標準伺服器中需要支援更多向量和矩陣運算(因為人工智慧演算法日益普及,而這些演算法正是需要大量此類運算),它可能會在後續的倚天晶片中切換到 V2 核心。華為技術旗下的晶片設計部門海思,在其 64 核鯤鵬 920 伺服器晶片中使用了 Arm 的 Neoverse「Ares」N1 核心,出於同樣的原因,它可能會在後續產品中採用 V2 核心。
Google據傳正在研發兩款定製的 Arm 伺服器晶片 – 一款與 Marvell 合作,另一款由其自己的團隊研發(如果傳言屬實的話),目前尚不清楚其使用的是哪些核心,但如果其中之一使用 V2 核心,我們也不會感到驚訝。Ampere Computing 已經從 Arm 的「Ares」N1 核心轉向其自有核心 ( 我們稱之為 A1),用於其 192 核「Siryn」AmpereOne 晶片。印度的先進計算發展中心 (C-DAC) 正在建構自己的用於 HPC 工作負載的「Aum」處理器,它基於 Arm 的 Neoverse V1 核心。正如我們之前指出的,富士通、Arm 和日本理化學研究所聯合建立的用於「富岳」超級電腦的 48 核 A64FX 處理器中的 512 位向量可以被視為一種 Neoverse V0 核心,因為 SVE 設計最初是為 A64FX 建立的。
我們還想知道,除了 Arm 在 Hot Chips 2023 上展示的基於 N2 核心的 CSS 伺服器晶片設計之外,為什麼沒有立即推出基於 V2 核心的 CSS 伺服器晶片設計。為什麼不能同時在 CSS 設計中使用 N2 和 V2 核心呢?我們認識到一些資料中心營運商更需要針對性價比進行最佳化,他們認為不需要那麼多向量指令集;軟體和工作負載是否會證明他們是對的,還有待觀察。但是,AWS 選擇 V1 核心,Nvidia 選擇 V2 核心,這是一個非常強烈的指標。Ampere Computing 的 A1 核心在向量指令集方面更類似於 N2 核心,擁有兩個 128 位引擎,因此雲端上這種大向量核心的行為並非普遍存在。
V2 IS LIKE A ROCKET
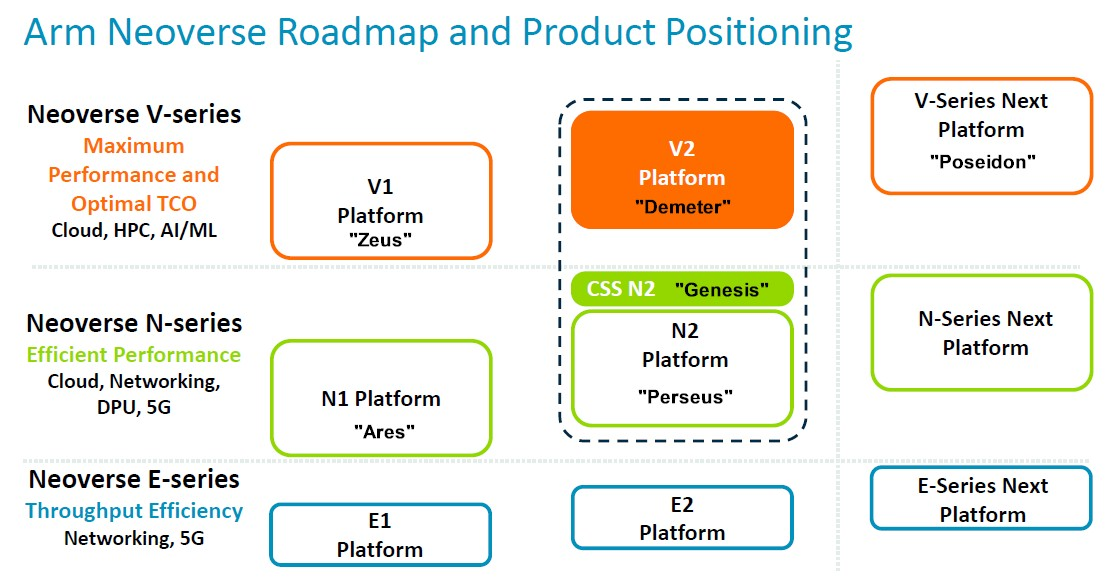
Arm 在 2020 年 9 月對其 Neoverse 核心和 CPU 設計進行了三叉化,將 V 系列高性能核心 (具有雙倍向量引擎) 與主系列 N 系列核心 (專注於整數性能) 分開,並新增了 E 系列 (專注於能源效率和邊緣計算的入門級晶片)。多年來,路線圖已經擴展和更新了多次,最新版本 (包括 N2 平台新增的 CSS 子系統變體) 在 Hot Chips 上展示:
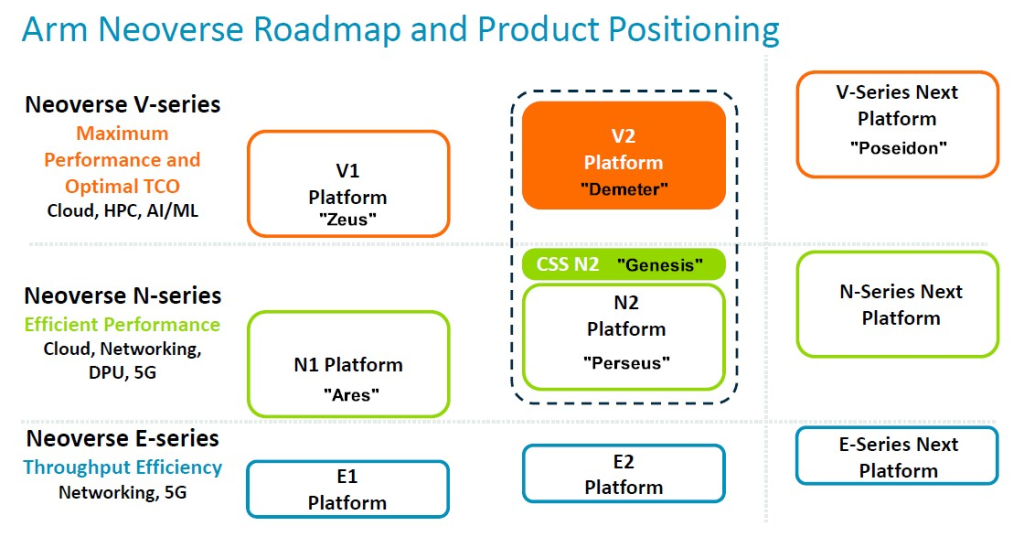
為了方便理解,我們新增了一些核心和平台程式碼名稱 (因為我們喜歡同義詞)。
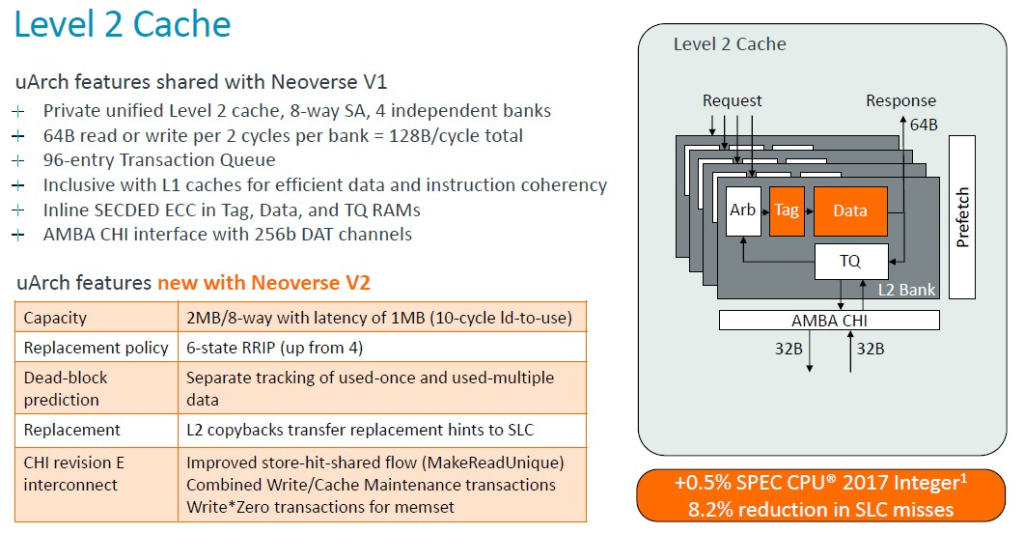
Magnus Bruce 是 Arm 公司的研究員暨首席 CPU 架構師,他在 Hot Chips 上介紹了 V2 平台,談論了架構以及相較於宙斯 V1 平台的變化。下表很好地總結了這一點:
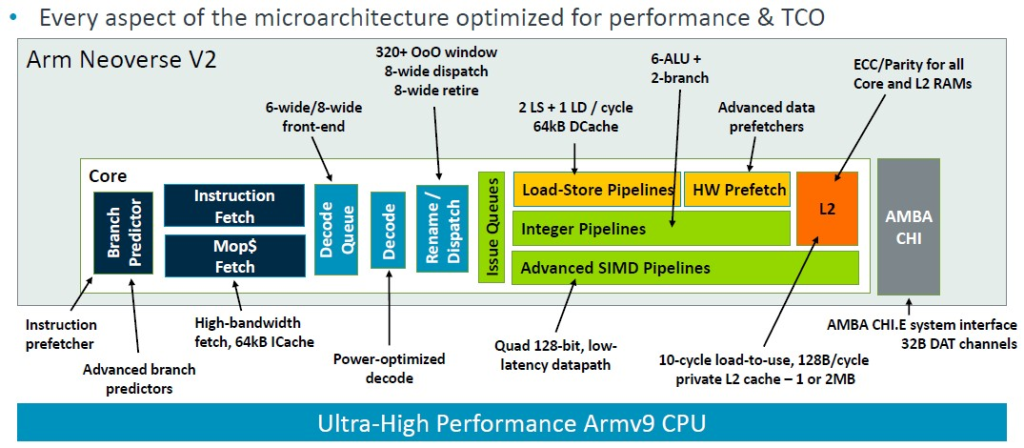
Bruce解釋說:「這個流水線的基礎是一個超前分支預測器,它充當指令預取器並且將提取與分支解耦。大型分支預測結構可以涵蓋非常龐大的真實伺服器工作負載。我們使用發出後讀取的物理暫存器文件,允許使用非常大的發出佇列,而無需承擔儲存資料的負擔。這對於解鎖指令級平行性 (ILP) 是必需的。我們使用低延遲和私有 L2 快取,低延遲 L1 和私有 L2 快取,以及最先進的預取演算法和激進的儲存到載入轉發,以使核心保持供給,並儘量減少氣泡和停頓。來自系統的動態反饋機制使核心能夠調節積極性並主動防止系統擁塞。這些基本概念使我們能夠擴展機器的寬度和深度,同時保持快速錯誤預測恢復所必需的短流水線。」
重要的一點是,這是一個 Armv9 實現,旨在淘汰該架構,與定義了十多年來 Arm 晶片的 Armv8 架構相比,它帶來了性能、安全性和可擴展性增強。
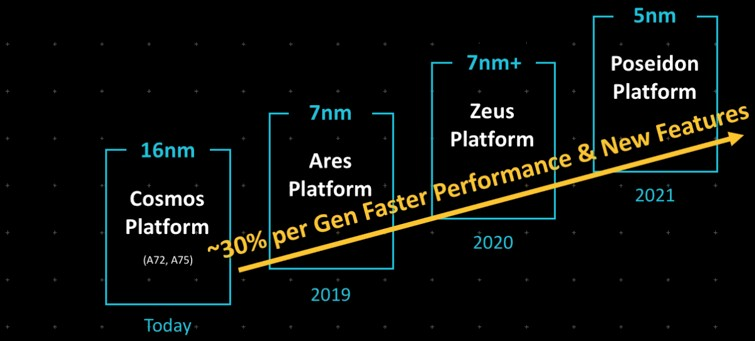
V2 晶片的架構調整雖然巧妙,但效果明顯。然而,正如 Arm 自己早在 2019 年設定的目標那樣,13% 的性能提升遠未達到每週期指令 (IPC) 性能提升 30% 的目標:
總之,以下是 V2 核心的分支預測器和提取單元以及 L1 快取的詳細資訊:

正如您所看到的,V1 核心的大部分功能都轉移到了 V2 核心,但 V2 核心也做了一些更新。許多佇列、表格和頻寬都翻了一番,但微操作快取實際上在轉移到 V2 設計時減少了。根據使用晶片模擬器對 V1 和 V2 進行建模的 SPEC CPU 2017 整數基準測試,V2 核心的這些調整使每週期指令增加約 2.9%。
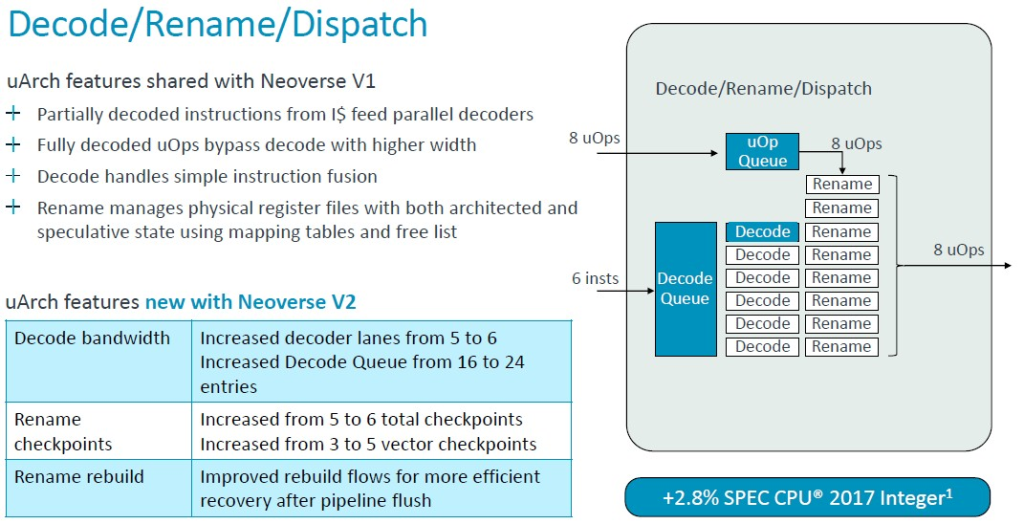
同樣,V1 核心在指令解碼和調度方面的一些微架構優勢也直接傳遞到了 V2 核心,但解碼通道和佇列略有提升。總體效果使 IPC 增加了 2.9%,再次由 SPEC CPU 2017 整數測試進行評估。(IPC 通常使用混合測試來計算,而不僅僅是 SPEC CPU 評分。但這正是我們獲得的結果。)
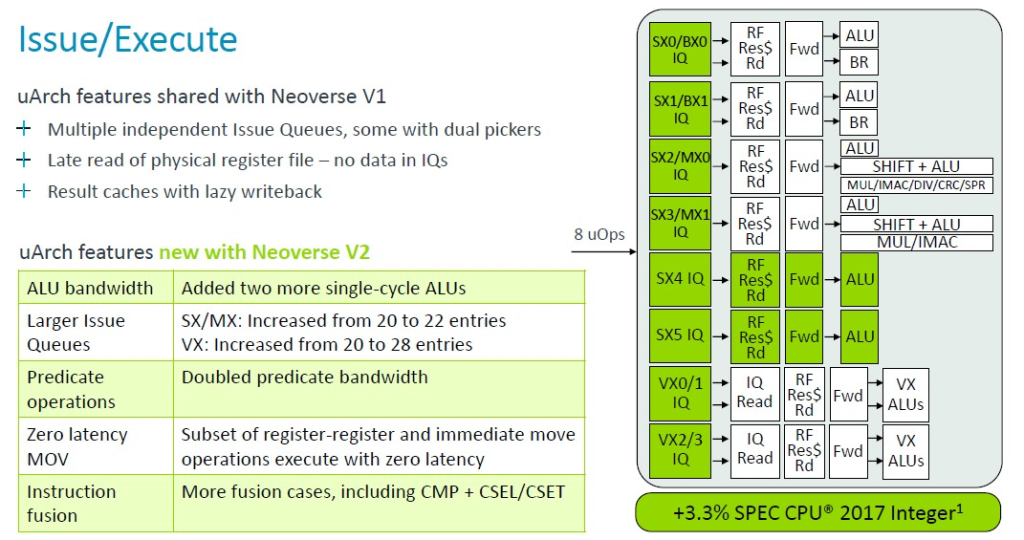
使用 V2 核心,Arm 架構師新增了兩個額外的單週期算術邏輯單元 (ALU),並增加了發出佇列的大小,以及將謂詞運算子的頻寬增加了一倍,這些調整以及其他一些調整,使在 2.8 GHz 歸一化後核心性能又增加了 3.3%。
與 V1 核心一樣,V2 核心也具有兩個負載/儲存管道和一個負載管道,但是表格尋找緩衝區 (TLB) 的條目數量從 40 個增加到 48 個,各種儲存和讀取佇列的容量也增大了。
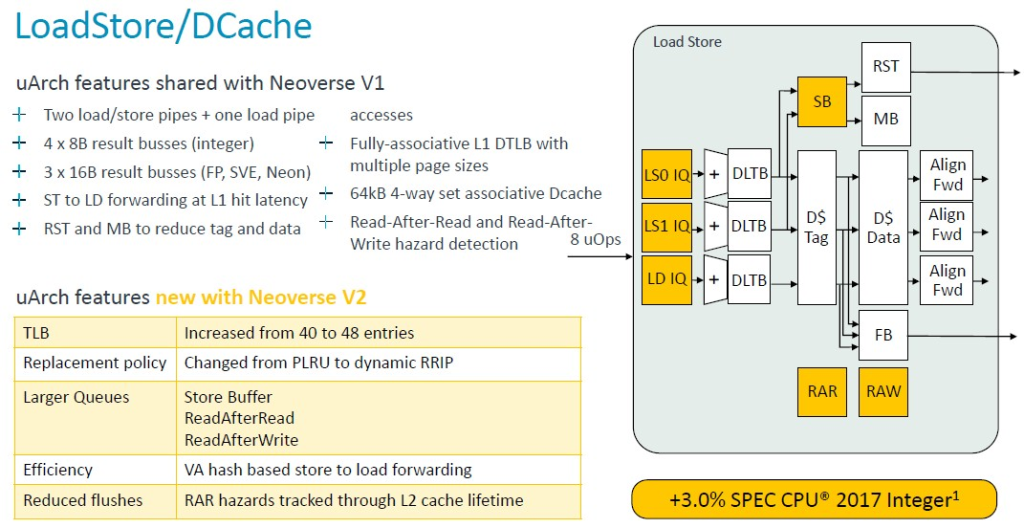
這項以及其他更改使 V2 核心性能又提高了 3%。
Arm 架構師通過更改硬體資料預取功能來獲得最大的性能提升:
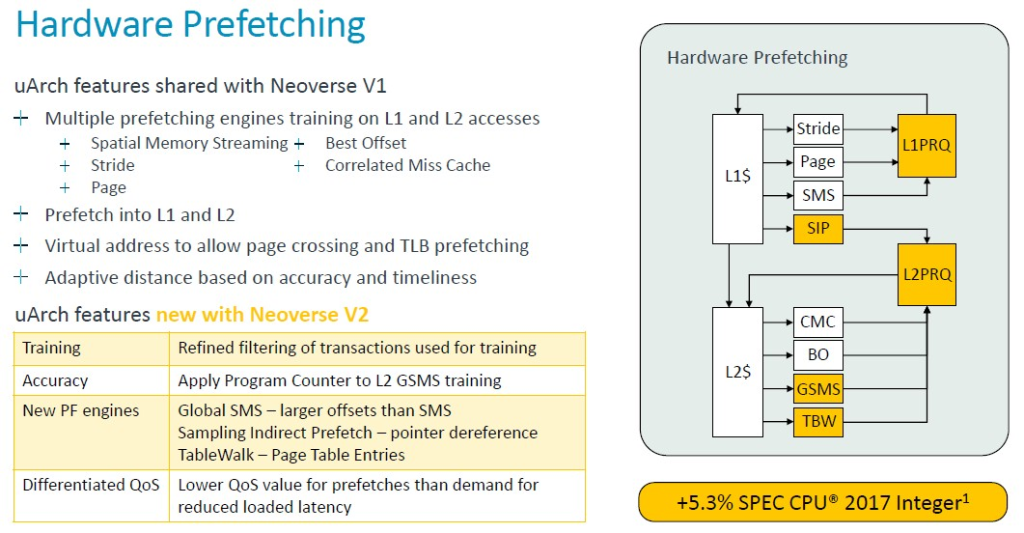
Bruce 解釋說:「Neoverse V1 已經擁有最先進的預取功能」,我們將讓他帶您瞭解這個關於預取增強功能的低層次解釋。深呼吸一下……「我們的預取器使用訓練多個引擎處理 L1 和 L2 未命中以及預取到 L1 和 L2 快取,它們通常使用虛擬地址來允許頁面穿越 – 這也使它們能夠充當 TLB 預取器。預取器利用來自互連網的動態反饋以及 CPU 內部 的精準性和及時性測量來調節其積極性。V2 通過改進訓練、通過更好的過濾和訓練操作提高精準性,並利用程序計數器在更多預取器中實現更好的相關性和更好地防止別名來建構 V1 硬體。還新增了新的預取引擎。L2 獲益於全域空間記憶體流引擎,該引擎增加了預取器可以覆蓋的偏移量範圍,並且大大優於舊的標準 SMS 引擎。我們新增了一個抽樣間接預取器,用於處理指針取消引用場景。這不是資料預測,而是學習指針作為其他負載的資料消耗模式。我們還新增了一個表遍歷預取器,用於將頁表條目預取到 L2 快取中。現在,所有這些新增的預取器及其積極性都可能在系統中造成擁塞。尤其是在共享資源(例如系統級快取或 DRAM)方面。我們為需求和預取提供差異化的 QoS 等級。這使我們能夠進行積極的預取,而不會損害需求請求的載入延遲。動態預取動態反饋將預取器積極性調節到可持續的水平。這些變化結合起來使 spec 管理器性能提高了 5.3%,但更重要的是,我們同時看到 SLC 丟失減少了 8.2%,因此我們以更少的 DRAM 流量獲得了更高的性能。」
以下是 L2 快取如何發揮其魔力:
L2 快取容量增加一倍並沒有帶來太大性能提升,但是減少系統級快取未命中率會間接提升性能。
以下是 IPC 的詳細計算方式:
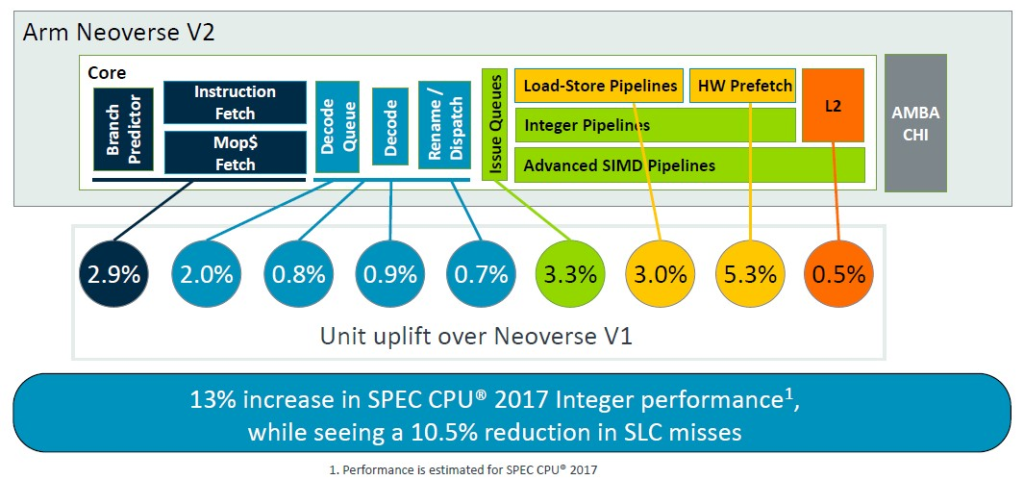
這些都是累加效應,而不是乘法效應,V2 核心在整數性能方面提升了 13% – 再次申明,這是基於模型的結果,並且僅使用 SPEC CPU 2017 整數測試 – 同時總體減少了 10.5% 的系統級快取未命中率。
每當推出新的核心或晶片時,都會根據性能、功耗和面積的相互影響來評估該核心或晶片。以下是 V1 和 V2 核心的對比:
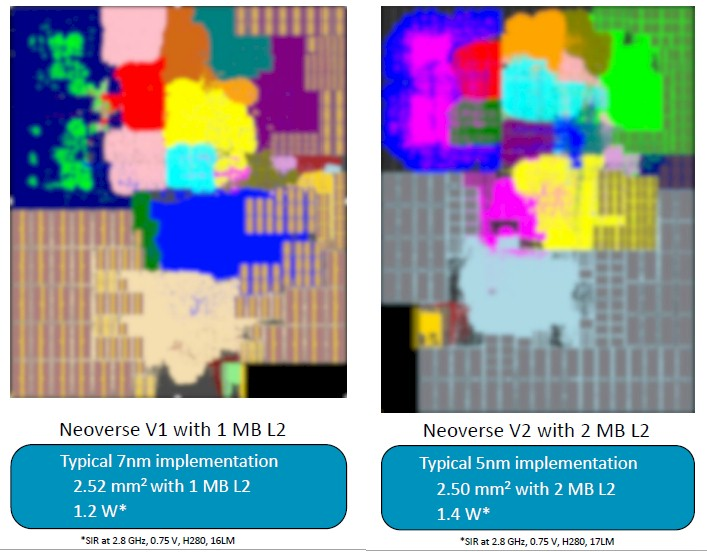
採用 7 納米工藝實現的 V1 核心擁有 2.5 平方毫米的面積,1 MB 的 L2 快取,功耗約為 1.2 瓦。V2 核心擁有略小的面積,但 L2 快取增加了一倍,達到 2 MB,功耗也增加了 17%。所有這些比較都基於 2.8 GHz 的時鐘速度歸一化。
當然,V2 不僅僅是一個核心,而是一個可以授權的平台規範:
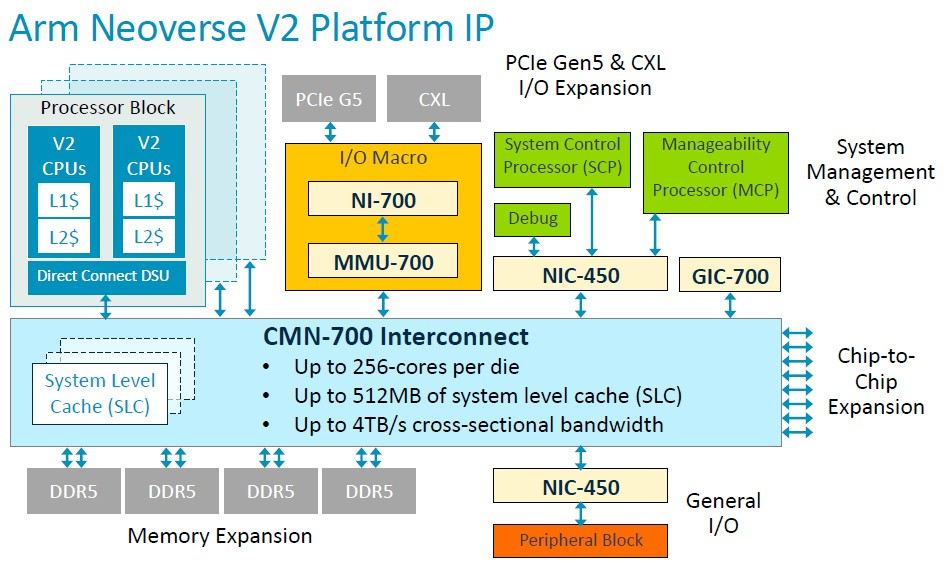
憑藉 CMN-700 互連網路,Arm 授權許可證持有者可以建構可擴展至 256 個核心和 512 MB 系統級快取的 V2 CPU,該互連網路可在整個網格上的所有核心、記憶體和 I/O 控製器之間提供 4 TB/秒的橫截面頻寬。
V2 核心的許多演示都側重於整數操作,但是在演講的問答環節中,Bruce 提到了關於向量性能的一些有趣之處。V1 核心擁有兩個 256 位 SVE1 向量引擎,但 V2 核心擁有四個 128 位 SVE2 向量引擎。正如 Bruce 所說,這是因為在四個單元上分散混合精度計算比在兩個單元上執行更容易(並且我們推測效率更高)。
但是,正如我們所說,除了 Nvidia 和可能還有 AWS 之外,誰會去授權 V2 核心呢?也許任何打算使用 V2 的人已經在進行定製設計,因此沒有理由製作 CSS 變體?