
原文:ARM NEOVERSE ROADMAP BRINGS CPU DESIGNS, BUT NO BIG FAT GPU
Gemini 翻譯,無校正
同樣的資料,電腦王的報導
Arm更新Neoverse產品路線圖,推出Neoverse CSS N3、V3等全新第3代Neoverse IP
CNBETA:
Arm新产品可加速创建定制数据中心芯片 时间缩短至不到一年
注意!令人洩氣的消息! Arm Neoverse 資料中心運算路線圖中加入了許多很棒的東西,但其中缺席的,正是資料中心等級的離散式 GPU 加速器。另一個缺席的則是更特定於矩陣運算的加速器,例如 Intel (實際上是 Habana Labs)、SambaNova Systems、Tenstorrent、Groq 或 Cerebras Systems 所研發的產品。
這真的很可惜。
考慮到 Nvidia 大肆掠取的利益(該公司以前幾乎收購了 Arm Holdings,並承諾如果其 400 億美元的收購案獲得地球上監管機構的批准,將通過 Arm 的授權機制來運行其 GPU 設計),就像使用超寬的聯合收割機一樣收割利潤,您本會認為市場會要求 Arm 提供比 Nvidia 現有「Hopper」H100/H200 和即將推出的「Blackwell」B100/B200 離散式 GPU 以及 AMD 現有「Antares」 Instinct MI300 和未來 Instinct MI400 離散式 GPU 更便宜的替代方案。
我們知道您在想什麼。為什麼我們沒有提到英特爾的離散式資料中心 GPU?嗯,英特爾的「Ponte Vecchio」Max 系列 GPU(除了美國阿貢國家實驗室的「Aurora」超級電腦內部的 GPU)在離散式 GPU 領域並不是真正的競爭者,但遺憾的是,如果英特爾現在能夠製造一百萬顆,那麼它就能賣出一百萬顆。而且英特爾要將 Max 系列 GPU 與 Gaudi 矩陣加速器融合成一個具有競爭力的產品,還需要很長的時間。
不,那艘船早已經駛離了,Google已經建立了 TPU、亞馬遜網路服務已經建立了 Trainium 和 Inferentia、微軟已經建立了 Maia、Meta Platforms 也在致力於其 MTIA 系列產品。資料中心基礎設施收入方面,幾乎一半的市場份額都由這些公司各自把持,嘗試建構新的 GPU 或矩陣架構風險太大,否則 Arm 就會去做。正是因為這種風險,我們可以說只有 Arm 才有可能做到並取得成功。
如果有人有勇氣創造出與 Nvidia 裝置在錯誤方面完全相容的 GPU,我們至少可以對這場主力框架複製之戰感到好笑,這場戰役是 IBM 與 Amdahl、富士通和日立(IBM 最終儘管經歷了幾場反壟斷訴訟還是贏了)之間的較量,又或者是資料中心領域,英特爾和 AMD 在 X86 架構上進行的史詩般的戰鬥(順便一提,AMD 贏了兩次)。
但唉,看起來 Arm 沒有胃口去做。其他公司也沒有。正是因為主機架構和 X86 架構發生的事情。
因此,Arm Holdings,作為一家再次獨立上市的公司,由於發行量稀少和非理性繁榮,其價值已經超過了其軟銀母公司,它將堅持專注於 CPU 領域,並憑藉其 Neoverse CPU 設計儘可能獲取人工智慧訓練和推理方面的資金。沒有比我們參加的 Arm 2024 Neoverse 路線圖簡報中包含的這張圖表更能說明這一點了:

認識你的定位。不要惹事。適可而止。
公平地說,上述三個 CPU 除了自家研發的加速器之外,都基於 Arm 架構,並且底部的三個 DPU 中至少有兩個也採用 Arm 架構。(我們不確定 Azure Boost 的情況,但是如果其中包含 CPU,那幾乎可以肯定基於某種 Arm 核心。)當 Arm 在 2011 年認真開始進軍資料中心領域的 X86 CPU 市場時,這種圖表還是一個夢想。Arm CPU 在超大規模擴展商和雲建構商資料中心的崛起絕對是成功的。
我們只是想要更多,僅此而已。我們認為資料中心中人工智慧工作負載的複雜性和獨特性需要更多。憤世嫉俗的人可能會說,Nvidia 願意斥資 400 億美元收購 Arm Holdings,是為了防止這家智慧財產權公司建立和授權殺手級 GPU,並且該交易讓 Arm 處於停滯狀態,而 Nvidia 則看到了 GenAI 浪潮即將到來。
即使是 Arm 自己概述不同類型資料中心工作負載性能向量的蜘蛛圖,也支援需要更多功能的論點:
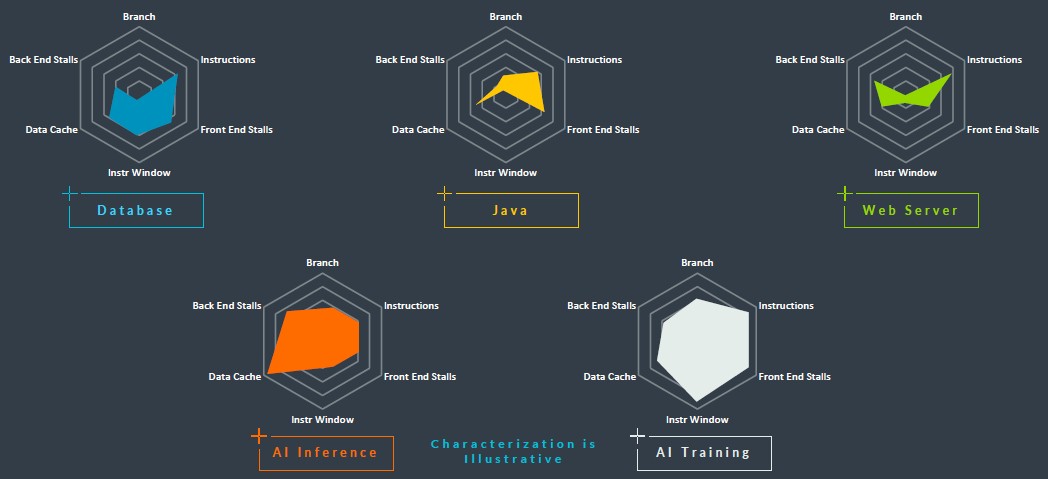
唉,到了 2024 年,我們從 Arm Holdings 得到的更多是隨著路線圖的擴展,各種 Neoverse 核心類型的延續,以及計算子系統(CSS)許可包,這些許可包將可用於高效能 V – class 核心以及去年夏天已經發布的N 級核心,“Genesis”知識產權圍繞“Perseus”N2 核心。
Nvidia 的「Grace」CG100 和亞馬遜的 Graviton4都是基於「Demeter」V2 核心,我們在去年夏天對此進行了深入研究。微軟的 128 核心 Cobalt 100 處理器是基於 Genesis CSS N2 設計,我們強烈懷疑傳聞中的 Google 的「Maple」Arm 伺服器 CPU 也將基於 CSS 跳躍啟動——也許是在「CSS 堆冬棧」上「波塞冬棧」V3核心或「赫爾墨斯」N3 核心。很大程度上取決於谷歌想要實現什麼目標以及何時實現。我們認為,不可避免的是,所有超大規模企業和雲端建置商都會在其資料中心部署混合使用 N 和 V 核心的 Arm CPU,並在邊緣部署 E 核心。當然,他們也會混合使用 X86 處理器,而這些處理器可能會在很長一段時間內佔據主導地位。但是,有時變化會很快發生,所以AMD,不要滿足於你的成就,英特爾,也不要滿足於AMD 的成就。
讓我們深入了解 Neoverse CPU 路線圖,從 2022 年 9 月的路線圖開始回顧一下,因為坦白說,它比 2024 年路線圖有更多細節:
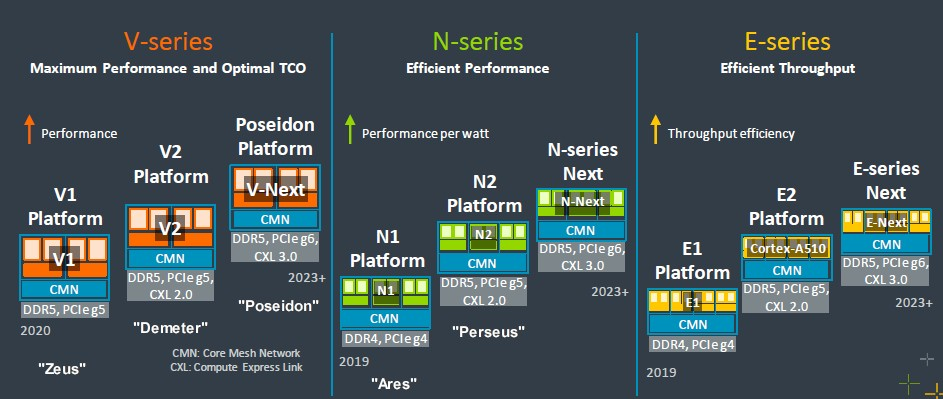
Neoverse 的努力已經有六年了,早在 2018 年 10 月,它開始的想法是每年製作一個新的核心和伺服器平台,並每年完成台積電製造流程步驟的變更。 2019年的「戰神」平台採用7奈米電晶體蝕刻,「宙斯」預計在2020年採用增強型7奈米工藝,「波塞冬」預計在2021年採用5奈米製程。也許比這種時鐘工作節奏更重要的是,人們期望——真的希望——在可預見的未來,Arm 能夠在每一代產品中實現 30% 的性能提升(部分通過架構,部分通過功能)。
然後 Neoverse 路線圖分為 N、V 和 E 核心,並且需要更多時間才能將核心投入使用。例如,Poseidon V3 核心最初預計在 2021 年推出,但現在才上市,然後在兩年前的路線圖中修改為更模糊的「2023+」。這些事情需要時間,而真正推動 Neoverse 路線圖的超大規模廠商和雲端建構商需要在全球大流行期間讓他們的晶片計畫井然有序,這確實擾亂了供應鏈和計畫。
我們認為,隨著 Neoverse 的發展,Arm 及其客戶的發展將會更加順利。
僅供參考,這是去年的 Neoverse 路線圖,該路線圖隨 CSS 發布而發布,為了清晰起見,我們添加了代號:
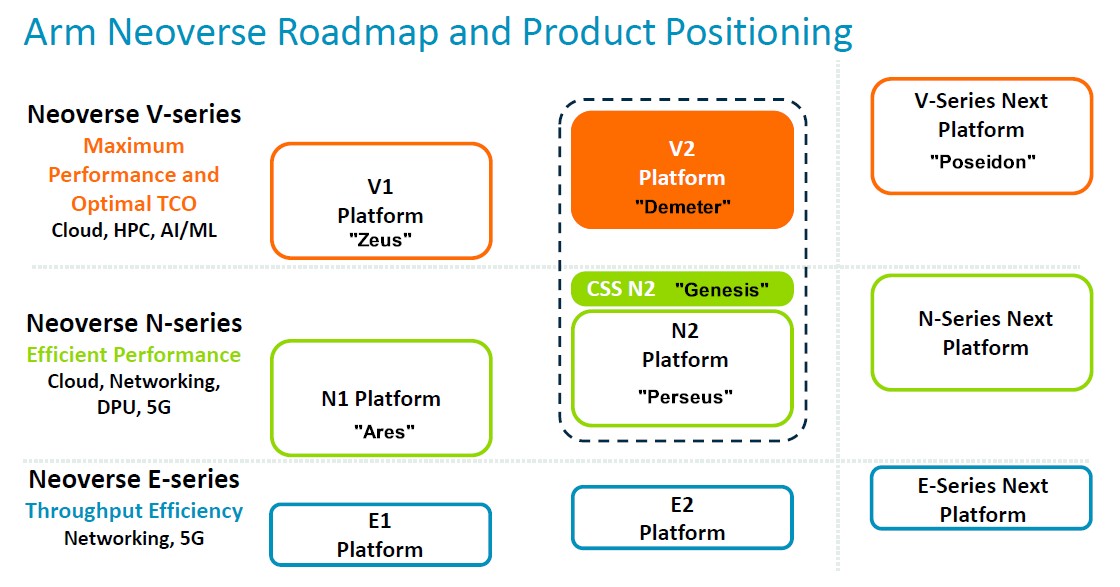
我們去年提到,需要針對 Nvidia 最初部署的 Demeter V2 核心提供一個 CSS 套件,但看起來這是不會發生了。好消息是 Poseidon 核心及其配套的 CSS 套件現在已經上市,Hermes N3 核心及其配套的 CSS 套件也已經上市,正如 2024 年的 Neoverse 路線圖所示:
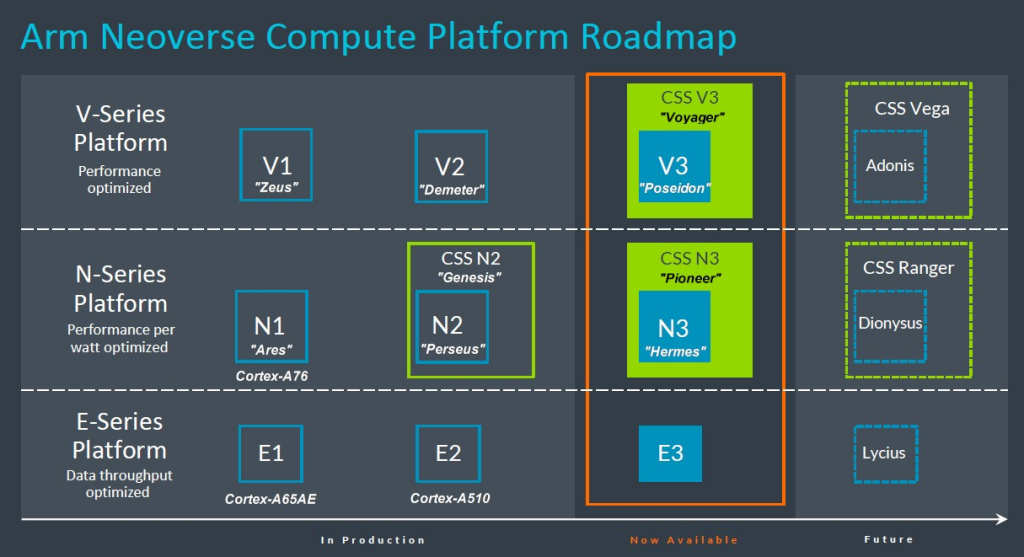
我們去年提到,需要針對 Nvidia 最初部署的 Demeter V2 核心提供一個 CSS 套件,但看起來這是不會發生了。好消息是 Poseidon 核心及其配套的 CSS 套件現在已經上市,Hermes N3 核心及其配套的 CSS 套件也已經上市,正如 2024 年的 Neoverse 路線圖所示:
我們不知道 N3 和 V3 CSS 套件的程式碼名稱,但我們猜測它們會遵循舊約聖經的命名方式,延續 Neoverse N2 IP 堆疊的 “Genesis” 名稱。事實上,它們的程式碼名稱分別是 “Voyager” (航海者) 對應 CSS V3 和 “Pioneer” (先驅者) 對應 CSS N3。
ARM 在 2024 年的路線圖中去掉了 X 軸上的年份,因此我們不知道後續的 “Adonis” V4 核心及其 “Vega” CSS 套件、後續的 “Dionysus” N4 核心及其 “Ranger” CSS 套件,以及後續的 “Lycius” E4 核心將在何時上市。ARM Neoverse 高層承諾會在未來提供更多細節。
以下是我們所知道的。CSS N3 套件以 32 個 N3 核心為基礎,並配備一對 DDR5 記憶體控製器、一對 I/O 控製器以及可選的 die-to-die 互連,用於建立計算複合體,我們預計這些複合體將以兩個複合體粘合在一起的形式構成一個插槽,提供 64 個核心。這些 N3 核心符合最新的 Armv9.2 規格。
N3 核心或 CSS N3 套件的製程技術尚未公佈,但我們認為它將支援台積電的 5 納米和 3 納米製程,以及三星和英特爾的對應製程。
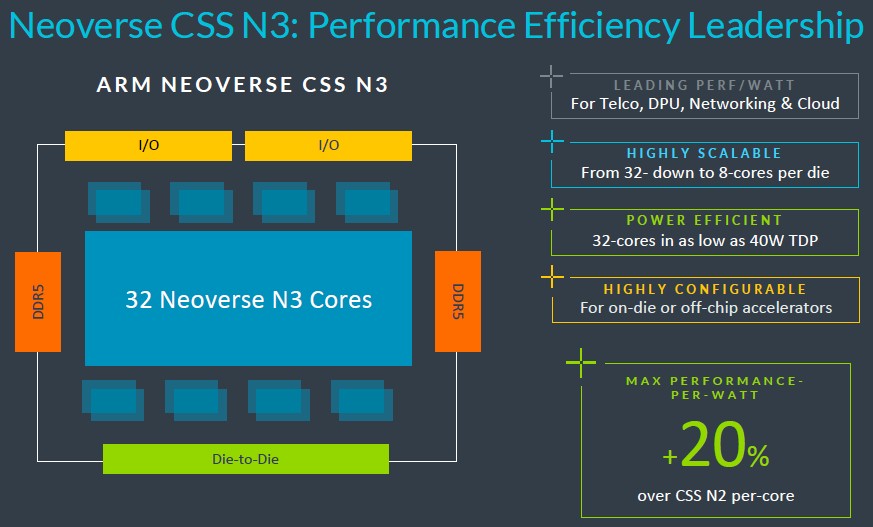
上述資料點表明,N3 CSS 套件可以在 40 瓦的熱設計功率下提供 32 個核心,這強烈暗示該設計將採用台積電的 3N 3 納米製程。
根據 Arm 的說法,N3 套件可以縮小到僅包含 8 個核心,おそらく會搭配一個 DDR 控制晶片和一個 I/O 控制晶片。從之前 2022 年 9 月的路線圖來看,我們原本猜測 N3 核心將被放入支援 DDR5 記憶體和 PCI-Express 6.0 外設控製器的套件中,並帶有 CXL 3.0 一致性覆蓋層。但如果以下描述的 CSS V3 套件是參考標準的話,那麼它可能會被限制在 PCI-Express 5.0 外設和 CXL 2.0。(我們並不是說它就是標準。)
我們不知道 N3 核心上的向量單元有多寬,或者有多少個向量單元,但是如果 N3 核心要在 CPU 上執行人工智慧推理和一些人工智慧訓練(這正是 Arm 所相信的),那麼它們將需要比 N2 核心更加強大。N2 核心擁有兩組 128 位向量,可以每個時鐘執行四個 FP64 運算,然後可以降低精度以獲得混合精度性能。N3 核心也可能會新增一個合適的矩陣數學單元(例如張量核心),但 Arm 沒有透露這一點。
如果歷史可以參考的話,Poseidon V3 核心可能會以類似的方式進行強化,擁有比 Hermes N3 核心兩倍的向量和矩陣運算能力。但我們目前還不知道這一點。Zeus V1 核心擁有兩組 256 位向量,在 Demeter V2 核心上則改為四個 128 位向量;兩者都可以在每個時鐘執行八次 FP64 運算,但後一種設計效率更高。將很有意思地看到 V3 核心在這方面會有什麼樣的變化。考慮到我們對 V1 核心所瞭解的,四個 256 位向量會顯得有些奇怪,而八個 128 位向量也可能會讓人覺得奇怪,直到您意識到這正是英特爾在“Sapphire Rapids” Xeon SP CPU 中建立 AMX 矩陣數學單元的方式。
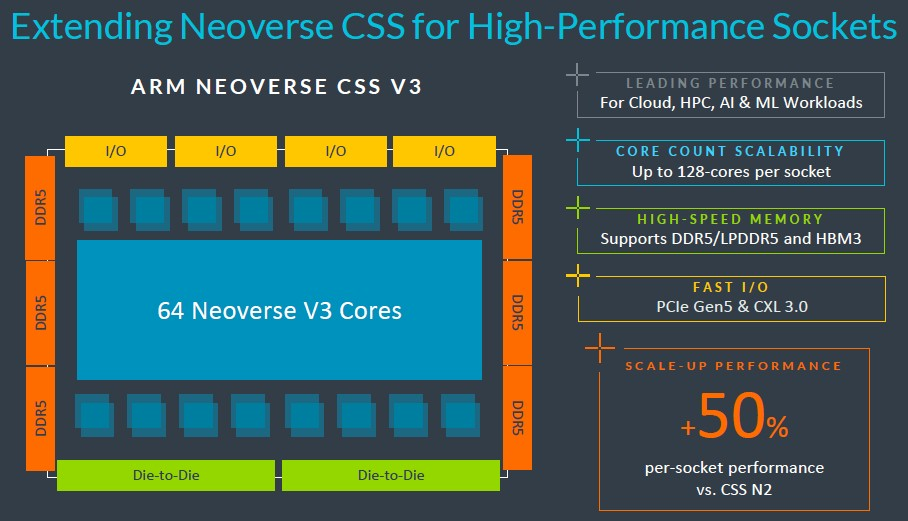
無論如何,基礎的 CSS V3 建構模組由 64 個 V3 核心、6 個 DDR5 記憶體控製器、4 個 PCI-Express 5.0 I/O 控製器以及一對 die-to-die 互連組成。2022 年 9 月的路線圖告訴我們,V3 世代將支援 PCI-Express 6.0 和 CXL 3.0。但事實上要到 V4 甚至可能是 N4 世代才會實現。(也可能 N3 首先支援 PCI-Express 6.0,而 V3 完全不支援。)
根據 Arm 的說法,這個 CSS V3 複合體的性能比標準的 CSS N2 複合體高出 50%,並且可以將其中兩個放置在一個封裝上,從而在一個插槽中擴展到 128 個核心。令我們驚訝的是它無法擴展到 256 個核心,但這可能是 CSS 的限制,而不是 V3 架構本身的限制。我們確信有人可以建構一個 256 核的 V3 插槽;然而,這在技術上或經濟上可能都說不通。
V3 套件將支援 DDR5 記憶體或 HBM 堆疊記憶體,看看全球是否有任何 CPU 製造商會採用 HBM 會很有趣。為什麼不呢?HBM 在 HPC 和 AI 方面的好處顯而易見,而且當金錢不是問題時(就像 GenAI 的情況一樣),為什麼不打造一輛性能怪獸呢?
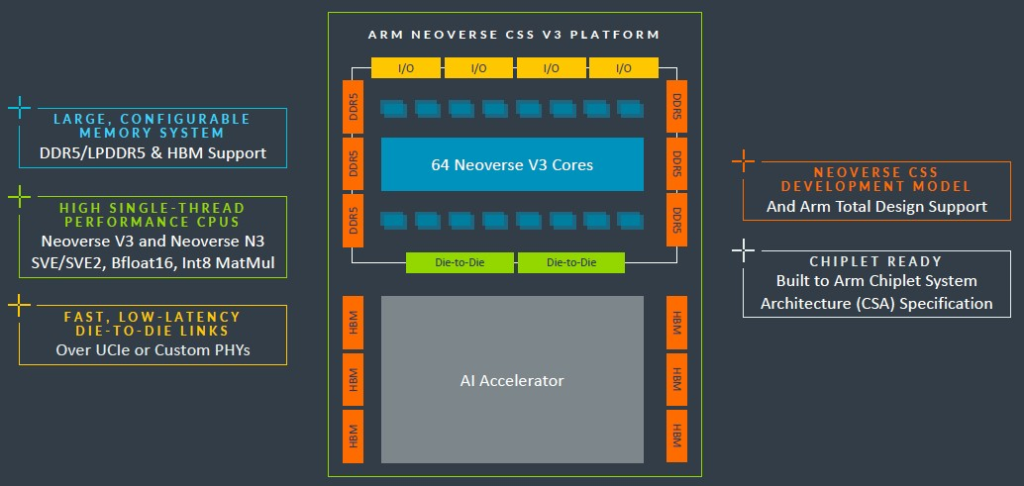
Arm 渴望指出,CSS V3 套件旨在直接緊密地連接到加速器,這對於 Nvidia 及其 Grace-Hopper 超級晶片複合體而言顯然非常重要。
為了吊讀者胃口,Arm 提供了 V2 核心相較於之前 N1 和 V1 核心以及過去兩代來自 Intel 和 AMD 的 X86 處理器的早期性能規格。讓我們來看看這些資訊:

這裡是另一個圖表,展示了 V3 相較於 V2 的性能表現,以及 N3 相較於 N2 在各種工作負載下的性能表現:
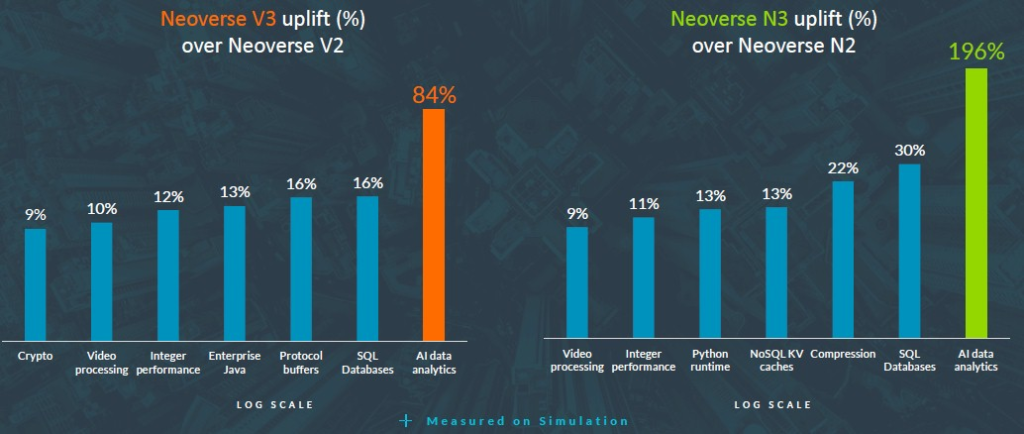
Arm 投入了大量精力來提升 XGBoost 的性能,XGBoost 是一種經典機器學習演算法,用於回歸、分類和預測。
為了增加趣味性,Arm 還提供了一些人工智慧推理基準測試,測試對像是一個擁有 70 億參數的相對較小的 LLaMA 2 大型語言模型。
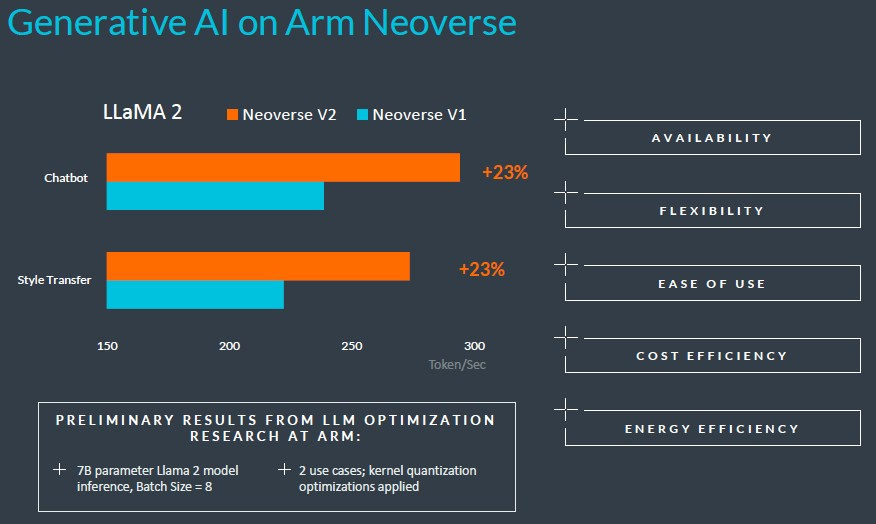
V3設計還沒有數據,這是大家都會關心的。